Tuning in unsupervised settings
In supervised modeling scenarios, we observe values of a target (or “response”) variable, and we measure the success of our model based on how well it predicts future response values. To select hyperparameter values, we tune them, trying many possible values and measuring how well each performs when predicting target values of test data.
In the unsupervised modeling setting of
tidyclust, there is no such objective measure of success.
Clustering analyses are typically exploratory rather than testable.
Nonetheless, the core tuning principle of varying inputs and quantifying
results is still applicable.
Specify and fit a model
In this example, we will fit a
-means
cluster model to the palmerpenguins dataset, using only the
bill length and bill depth of penguins as predictors.
(Please refer to the k-means vignette for an in-depth discussion of this model specification.)
Our goal will be to select an appropriate number of clusters for the model based on metrics.
First, we set up cross-validation samples for our data:
penguins_cv <- vfold_cv(penguins, v = 5)Next, we specify our model with a tuning parameter, make a workflow,
and establish a range of possible values of num_clusters to
try:
kmeans_spec <- k_means(num_clusters = tune())
penguins_rec <- recipe(~ bill_length_mm + bill_depth_mm,
data = penguins
)
kmeans_wflow <- workflow(penguins_rec, kmeans_spec)
clust_num_grid <- grid_regular(num_clusters(),
levels = 10
)
clust_num_grid
#> # A tibble: 10 × 1
#> num_clusters
#> <int>
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
#> 6 6
#> 7 7
#> 8 8
#> 9 9
#> 10 10Then, we can use tune_cluster() to compute metrics on
each cross-validation split, for each possible choice of number of
clusters.
res <- tune_cluster(
kmeans_wflow,
resamples = penguins_cv,
grid = clust_num_grid,
control = control_grid(save_pred = TRUE, extract = identity),
metrics = cluster_metric_set(sse_within_total, sse_total, sse_ratio)
)
res
#> # Tuning results
#> # 5-fold cross-validation
#> # A tibble: 5 × 5
#> splits id .metrics .notes .extracts
#> <list> <chr> <list> <list> <list>
#> 1 <split [266/67]> Fold1 <tibble [30 × 5]> <tibble [0 × 4]> <tibble>
#> 2 <split [266/67]> Fold2 <tibble [30 × 5]> <tibble [0 × 4]> <tibble>
#> 3 <split [266/67]> Fold3 <tibble [30 × 5]> <tibble [0 × 4]> <tibble>
#> 4 <split [267/66]> Fold4 <tibble [30 × 5]> <tibble [0 × 4]> <tibble>
#> 5 <split [267/66]> Fold5 <tibble [30 × 5]> <tibble [0 × 4]> <tibble>
res_metrics <- res |> collect_metrics()
res_metrics
#> # A tibble: 30 × 7
#> num_clusters .metric .estimator mean n std_err .config
#> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 1 sse_ratio standard 1 e+0 5 0 pre0_m…
#> 2 1 sse_total standard 2.25e+3 5 1.20e+2 pre0_m…
#> 3 1 sse_within_to… standard 2.25e+3 5 1.20e+2 pre0_m…
#> 4 2 sse_ratio standard 3.26e-1 5 5.40e-3 pre0_m…
#> 5 2 sse_total standard 2.25e+3 5 1.20e+2 pre0_m…
#> 6 2 sse_within_to… standard 7.35e+2 5 4.78e+1 pre0_m…
#> 7 3 sse_ratio standard 2.04e-1 5 8.36e-3 pre0_m…
#> 8 3 sse_total standard 2.25e+3 5 1.20e+2 pre0_m…
#> 9 3 sse_within_to… standard 4.60e+2 5 3.49e+1 pre0_m…
#> 10 4 sse_ratio standard 1.55e-1 5 8.07e-3 pre0_m…
#> # ℹ 20 more rowsChoosing hyperparameters
In supervised learning, we would choose the model with the best value of a target metric. However, clustering models in general have no such local maxima or minima. With more clusters in the model, we would always expect the within sum-of-squares to be smaller.
A common approach to choosing a number of clusters is to look for an “elbow”, or notable bend, in the plot of WSS/TSS ratio by cluster number:
res_metrics |>
filter(.metric == "sse_ratio") |>
ggplot(aes(x = num_clusters, y = mean)) +
geom_point() +
geom_line() +
theme_minimal() +
ylab("mean WSS/TSS ratio, over 5 folds") +
xlab("Number of clusters") +
scale_x_continuous(breaks = 1:10)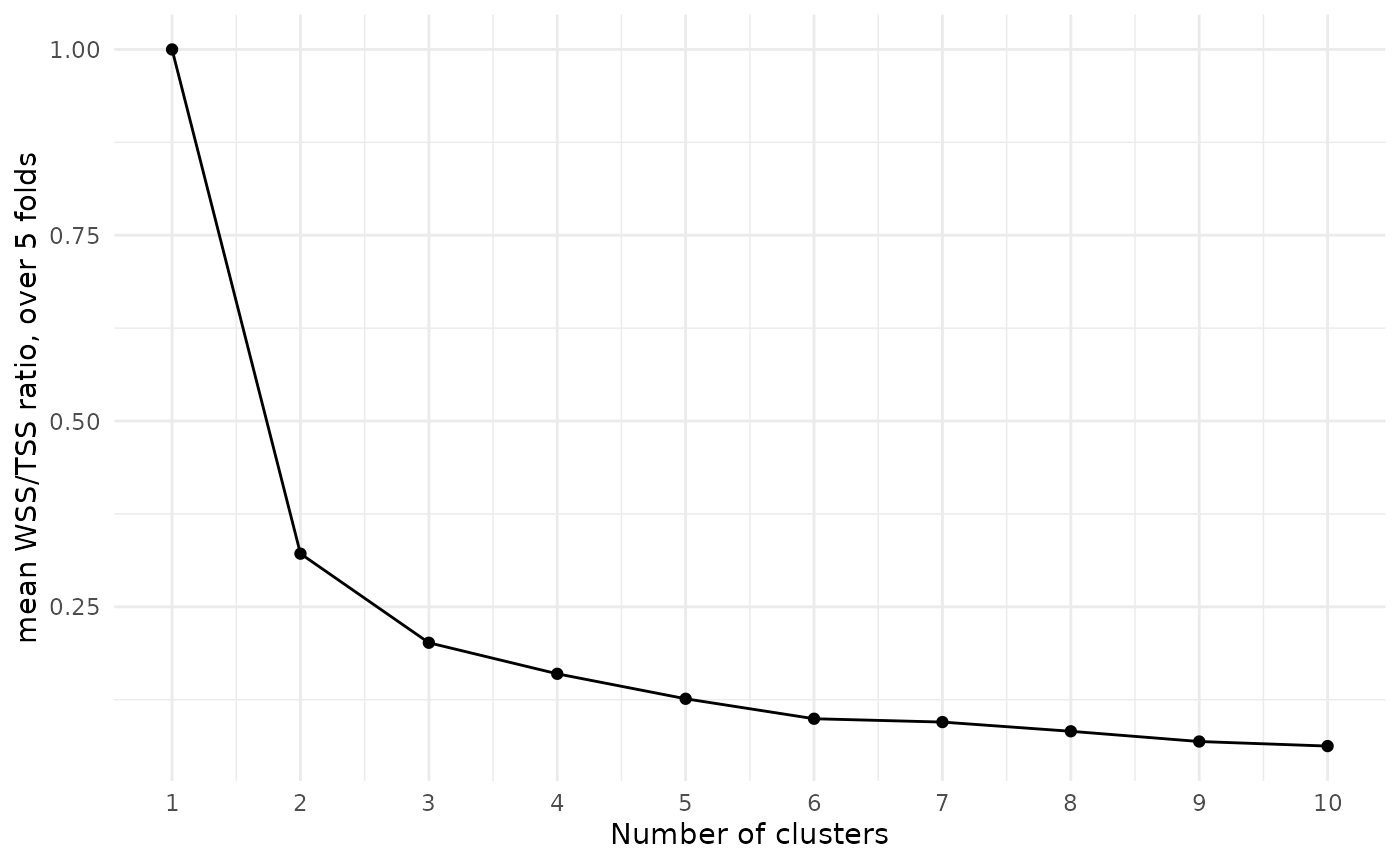
At each increase in the number of clusters, the WSS/TSS ratio decreases, with the amount of decrease getting smaller as the number of clusters grows. We might argue that the drop from two clusters to three, or from three to four, is a bit more extreme than the subsequent drops, so we should probably choose three or four clusters.
Custom distance functions
All tidyclust metrics accept a dist_fun argument that
controls how distances are computed. The philentropy
package, which tidyclust uses internally, supports many distance and
similarity measures. To see all available methods:
philentropy::getDistMethods()
#> [1] "euclidean" "manhattan" "minkowski"
#> [4] "chebyshev" "sorensen" "gower"
#> [7] "soergel" "kulczynski_d" "canberra"
#> [10] "lorentzian" "intersection" "non-intersection"
#> [13] "wavehedges" "czekanowski" "motyka"
#> [16] "kulczynski_s" "tanimoto" "ruzicka"
#> [19] "inner_product" "harmonic_mean" "cosine"
#> [22] "hassebrook" "jaccard" "dice"
#> [25] "fidelity" "bhattacharyya" "hellinger"
#> [28] "matusita" "squared_chord" "squared_euclidean"
#> [31] "pearson" "neyman" "squared_chi"
#> [34] "prob_symm" "divergence" "clark"
#> [37] "additive_symm" "kullback-leibler" "jeffreys"
#> [40] "k_divergence" "topsoe" "jensen-shannon"
#> [43] "jensen_difference" "taneja" "kumar-johnson"
#> [46] "avg"There are two different dist_fun interfaces depending on
which metric you are using.
Silhouette metrics
silhouette_avg() and silhouette() expect a
single-argument function that takes a data frame and returns a
dist object — the same interface as
philentropy::distance (the default):
kmeans_fit <- kmeans_wflow |>
finalize_workflow(list(num_clusters = 3)) |>
fit(penguins)
man_dist <- function(x) philentropy::distance(x, method = "manhattan")
silhouette_avg(kmeans_fit, new_data = penguins, dist_fun = man_dist)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 silhouette_avg standard 0.491SSE metrics
sse_within_total(), sse_total(), and
sse_ratio() expect a two-argument function
function(x, y) that computes distances between two matrices
(the cluster centroids and the observations). The default is
philentropy::dist_many_many with Euclidean distance:
man_dist2 <- function(x, y) philentropy::dist_many_many(x, y, method = "manhattan")
sse_within_total(kmeans_fit, dist_fun = man_dist2)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 sse_within_total standard 3620.